|
<< Click to Display Table of Contents >> Data-tracing |
  
|
|
<< Click to Display Table of Contents >> Data-tracing |
|
Performance and memory/file considerations Data-tracing is activated per default in Gekko >= 3.1.16. This tracing has some performance costs, and execution time used on data-tracing is shown as a percentage after each Gekko job (often, this percentage is quite low). The .gbk databanks become larger, depending upon the number of data-traces. You may look into a .gbk databank file if you open it as a .zip file: the trace.data file inside stores all traces. If you prefer, you can just remove this file manually from the gbk .zip file to get rid of all traces. Alternatively, use READ/WRITE/OPEN with option <trace = no>.
NOTE: When running the same series statements again and again iteratively (for instance, iterating over rows and columns in an input-output table until convergence), you may consider switching off data-tracing with option databank trace = no;. For such solver-like scenarios, data-tracing may slow down the calculations needlessly.
To switch off data-tracing, set this option: option databank trace = no; |
Data-tracing uses time-shadowing, that is, a trace may be deleted if the time periods it covers are completely "shadowed" (replaced) by one or more newer traces. For instance with x <2021 2022> = 1; x <2022 2022> = 2;, the series x contains two traces: trace t1 is defined for 2021, and trace t2 is defined for 2022. In that sense, trace t2 "shadows" parts of trace t1. If now a third statement x <2021 2021> = 3; is added, trace t1 is removed completely since only trace t2 and t3 are relevant. Cf this:
reset; |
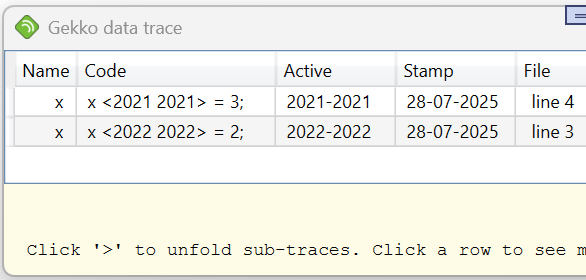
The trace x <2021 2022> = 1; has been "time-shadowed" and thus removed. For each trace, the "Active" field describes which periods out of the original period have not been "shadowed" by subsequent traces.
Traces are a graph
Nested data-traces may seem like a tree structure, but they are really a graph. Consider this example:
reset; |
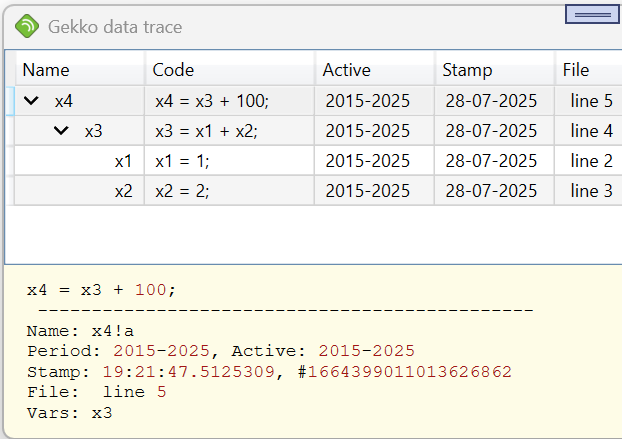
When unfolding the traces of x4, it is seen that x4 depends upon x3, which in turn depends upon x1 and x2. If we depict the timeseries objects as dotted boxes and the traces a solid boxes, we can depict the traces as follows:
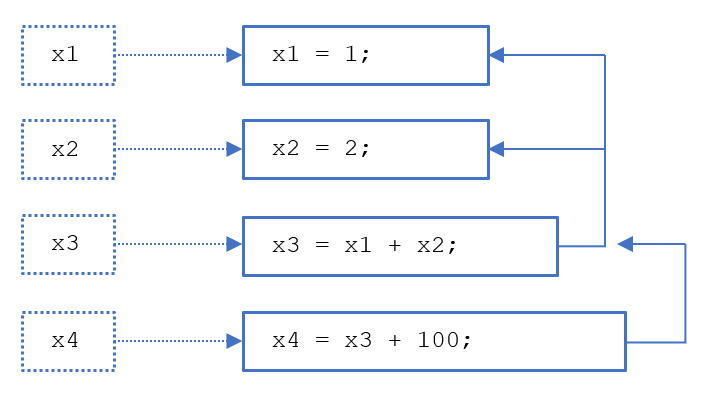
Starting from the series x1, this will only show the trace x1 = 1;. Similarly regarding series x2. Then series x3 has the trace x3 = x1 + x2;, but also the sub-traces x1 = 1; and x2 = 2;. The series x4 has the trace x4 = x3 + 100;, the sub-trace x3 = x1 + x2; and the sub-sub-traces x1 = 1; and x2 = 2;. Thus, for instance, the trace x1 = 1; can be reached in three ways: from series x1 itself, from series x3 (sub-trace) and from series x4 (sub-sub-trace).
All the four traces have depth 0, because they are all directly connected to a timeseries, cf. the result of tracestats();:

Now we can try to delete the first three series before showing traces:
reset; |
The trace viewer shows the same contents, but tracestats() shows something different:

There are still 4 reachable traces, but only 1 at depth 0. This is because the traces now looks like this:
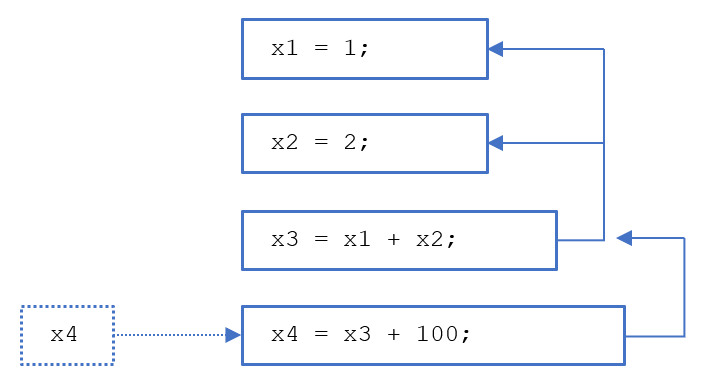
The series objects x1, x2 and x3 are removed, but their traces live on because of their "historical" impacts on series x4. In general, it pays off to think of traces as an interconnected graph structure, where many "paths" may lead to the same trace object.
Data-traces typically accumulate. If the data-trace parts of .gbk databanks become too large when running Gekko jobs, pruning/discarding some of these or alternatively sending them off to long-term storage may become an option. Each Gekko data-trace is universally unique, since it has an ID consisting of a time stamp (to millisecond precision) and a large random number (this is what is shown in the "Stamp" section of the data-trace viewer). Because of this uniqueness, data-traces can be removed from one databank and sent off to some other storage/backup databank, with the option of always being able to restore the traces again if needed.
When pruning or storing data-traces, criteria for doing this could be depth (as defined above, since it depicts the level of indirection), time stamp (newer traces are often most important) or active periods (if the remaining active period for a trace is old, it may not be too important to keep).
Archive databank
Traces may make a gbk databank large and/or slow to read/write. It is planned to provide functionality to prune off traces from a gbk databanks and store them in an "archive" trace databank.